【Stable Diffusion】如何借助AI完成绘画?
AI绘画概述
绘图过程(Diffusion扩散)
-
条件输入
常用的文生图(txt2img)中首先要做的就是输入提示词了,这些输入的提示词会在SD WebUI内置的文本编码器(TextEncoder)中被编码为数字,使其可以被AI看懂,然后送入Text Transformer得到生图条件。
-
随机种子
开始生成前会随机获得一串数字,用于形成一幅随机的噪声图,作为AI绘图的“画板”。如下是一张256×256的RGB随机噪声图。

-
图像生成(去噪)
在潜空间(Latent Space)中,AI会根据输入条件对噪声图进行去噪,即“采样”,经过多次的反复去噪,最后形成一张压缩过的“成品图”。
-
变分自编码器(VAE)
这一步是将潜空间中被压缩的“成品图”扩大成为我们可以看到的正常图片


Stable Diffusion
目前市面上已经有了许多的用于AI绘画的平台,例如DALL·E、MidJourney、NovelAI,2022年8月,Stable Diffusion诞生了,无需极为强劲的性能就可以运行在日常使用的电脑上。并且由于其全面开源的特性,你可以在自己的电脑上直接完成部署,以及免费、不限量地生成AI绘画图片。
AUTOMATIC1111将开源的Stable Diffusion做成了一款可以在浏览器中直接操作的“应用”,即Stable Diffusion web UI,借助它,可以将原本繁琐的代码层面的参数调校集成到一个Web页面中,通过WebUI,还可以使用到许多已发布的拓展插件。
安装
B站的秋葉aaaki老师将Stable Diffusion WebUI以及其所需环境都合并为了整合包,无需安装git、python、cuda等任何内容,无需任何配置,解压就可以使用,安装方式详见视频:秋葉aaaki - Stable Diffusion整合包
安装完成WebUI本体,以及后续可能会用到的模型等,占用空间可能达到甚至150-200G,所以要注意存放位置哦。
一些概念
模型(Model)
模型是AI在绘画过程中的参考,是由大量的图像经由AI深度学习训练得出的成果。借助模型,可以让AI完成某一类效果的绘制实现,是AI绘图过程中极其重要的一个部分。文件大小一般在几个G不等,文件后缀为.safetensors、.ckpt。
国内外有许多优秀的模型站点,诸如Hugging Face、Civitai,都是囊括了大量模型的宝库。
一些常见实用模型:
二次元风格
关键词:illustration, painting, sketch, drawing, painting, comic, anime, catoon
2.5D风格
关键词:photography, photo, realistic, photorealistic, RAW photo
真实系风格
关键词:3D, render, chibi, digital art, concept art, {realistic}
其他
词嵌入(Embeddings)
也写作Textual Inversion(文本倒置),作用是给AI解释部分字、词的含义。这些内容可能是难以理解的多词组合,或者是特定形象的呈现描述,可以理解为用已知的内容描述未知的内容,或者一个字典的书签,一个数据的指针。文件大小通常在20~100K,文件后缀为.pt、.safetensors。
比如解决AI不会画手的问题,可以使用这些Embeddings处理:
- EasyNegative(二次元)
- bad_prompt Negative(二次元)
- Deep Negative(真人)
低秩适应模型(LoRA)
LoRA(Low-Rank Adaptation Models),用于向AI传递、描述一个特征准确、主体清晰的形象,可以理解为一张彩页,上面详细记载了某个特定呈现的细节、特点。文件大小通常在200M以内,文件后缀为.safetensors。
触发LoRA的方法:<lora:LoRA名称>,设置权重在0.5-0.8可以保留确切特征但减弱对画面风格的影响。某些LoRA还提供了特定的提示词以强化调用的效果,可以一并写在提示词内。
超网络(Hypernetwork)
与LoRa类似,HyperNetwork一般用于改善生成图像的整体风格(画风),大小在200M以内,文件后缀为.pt。Hypernetwork与LoRA很像,它们都很小且仅修改cross-attention模块,区别在于后者是通过改变权重修改,而Hypernetwork则是通过插入额外的网络改动cross-attention模块。
书写提示词
- 提示词(Prompt),可以让AI知道你希望它完成什么内容。尽管称为AI绘画,但它其实无法理解你与它描述的自然语言是什么意思,因此,需要给AI提供的内容则需要通过它可以理解的方式。
- 在SD中,提示词分为两个部分:正向提示词与反向提示词,顾名思义,AI会按照正向提示词去完成创作,但会尽量避免反向提示词中出现的内容。
- 提示词需要使用英文书写,并且是以词组构成,因此并非像是与人描述一样使用长的复杂句。词组之间使用半角逗号分隔。
正向提示词
注:以下内容均整理自20分钟搞懂Prompt与参数设置,你的AI绘画“咒语”学明白了吗?
内容型提示词
-
人物及主题特征
-
服饰穿搭:white dress
-
发型发色:blonde hair, long hair
-
五官特点:small eyes, big mouth
-
面部表情:smiling
-
肢体动作:stretching arms
-
-
场景特征
-
室内/室外:indoor / outdoor
-
大场景:forest, city, street
-
小细节:tree, bush, white flower
-
-
环境光照
-
白天/黑夜:day / night
-
特定时段:morning, sunset
-
光环境:sunlight, bright, dark
-
天空:blue sky, starry sky
-
-
画幅视角
-
距离:close-up, distant
-
人物比例:fullbody, upper body
-
观察视角:from above,view of back
-
镜头类型:wide angle, Sony A7 III
-
-
其他画面要素
-
通用内容:
1
SFW, (masterpiece:1,2), best quality, masterpiece, highres, original, extremely detailed wallpaper, perfect lighting,(extremely detailed CG:1.2),
标准化提示词
-
画质
-
通用高画质:best quality, ultra-detailed, masterpiece, hires, 8k
-
特定高分辨率类型:extremely detailed CG unity 8k wallpaper(超精细的8KUnity游戏CG),unreal engine rendered(虚幻引擎渲染)
-
-
画风提示词
-
插画风:llustration, painting, paintrush
-
二次元:anime, comic, game CG
-
写实系:photorealistic, realistic, photograph
-
-
其他特殊要求
反向提示词
通用内容:
- 图像质量描述:
- Worst quality: 最差质量
- Low quality: 低质量
- Normal quality: 正常质量
- Lowres: 低分辨率
- Blurry: 模糊
- Unclear eyes: 眼睛不清晰
- 皮肤瑕疵:
- Skin spots: 皮肤斑点
- Acnes: 痘痘
- Skin blemishes: 皮肤瑕疵
- Age spot: 老年斑
- 审美负面描述:
- Ugly: 丑陋
- Morbid: 病态
- Mutilated: 残缺
- Tranny: 涉及性别问题(潜在冒犯性)
- 绘画技巧问题:
- Duplicate: 重复
- Poorly drawn hands: 手绘不好
- Bad anatomy: 解剖结构不准确
- Bad proportions: 比例不准确
- Extra limbs: 多余肢体
- Disfigured: 形象被扭曲
- Missing arms: 缺失手臂
- Extra legs: 多余腿
- Fused fingers: 手指融合
- Too many fingers: 手指过多
- Missing fingers: 缺失手指
- Extra digit: 额外数字或手指
- Bad hands: 手部描绘不好
- Extra arms and legs: 额外手臂和腿
权重配置
基础设置
- 圆括号
(prompt):×1.1(可叠加,每层叠加都 ×1.1) - 括号+数字
(prompt:1.5):指定权重倍数 - 大括号
{prompt}:×1.05(可叠加,每层叠加都 ×1.05) - 中括号
[prompt]:×0.9(可叠加,每层叠加都 ×0.9)
进阶设置
-
混合
a|b:混合两个描述同一对象的提示词要素【例】
white|yellow flower:生成黄色和白色混合的花 -
迁移
[|]:连续生成具有多个不同特征的对象,不断迁移【例】
[white|red|blue] flower:先生成白花,再生成红花,再生成蓝花。 -
迭代
(::):与采样进程关联,一定阶段以后再生成特定对象。【例】
(white flower:bush:0.8):进程到达80%(0.8)之前生成白花,80%之后再生成灌木。【例】
(white flower::0.8):进程到达80%(0.8)之前生成白花,80%之后删除该提示词。
生图配置
采样迭代步数(Steps)

如前面所说,AI在进行图像创作的过程中是经过了多次迭代的,这里设置的步数即是AI生图的迭代次数,一般设置在20-40,不同的模型、LoRA等一般有不同的推荐步数。通常迭代次数越多,产出的图像就会越清晰/细致,但生图时间也会更长。
采样方法(Sampler)
采样方法就是AI生成图像时的特定算法,同样的种子和提示词在不同的采样方法下生出的图会也出现不同,通常模型、LoRA的作者会提供建议使用的采样方法,以达到可以实现的最好效果。
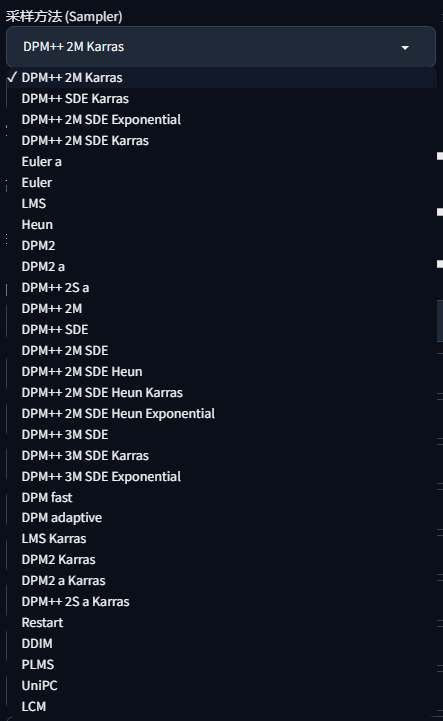
- Euler系列(欧拉方法):
- Euler:中规中矩、简单直接、不易出错
- Euler a:Euler的前代,多样性较高
- LMS:Euler的衍生版本,但容易出现色块
- Heun:Eular的改进算法,在每一步中预测两次噪声,速度比Eular慢一倍
- DPM系列:
- DPM fast:细节少,质量较低
- DPM adaptive:无视迭代步数,质量较高但时间较长
- DPM2:DPM的2代算法,质量比1代高但速度很慢,可以使用1代增加迭代步数替代
- 后缀:
- a:前代算法,祖先采样器,每一步都会产生新的噪点,生成更多样
- 2S:单步算法
- 2M:二阶多步采样算法,相当于2S的进阶
- 3M:与2M类似,但需要更多的迭代步数,效果会更好一些
- SDE:将OED(常微分方程)求解器更换为SDE(随机微分方程)的版本
- Karras:Karras算法,噪点收敛速度不断降低(收敛步长缩短),可以在更高迭代数量下提高图像质量
- Huen:Euler改进算法,质量更好,但速度慢
- Exponential:画面更柔和,但细节更少
- UniPC:2023年新推出的算法,10步以内即可生成高质量图像
总结:
- 简单快捷:Eular、Heun
- 性价比高(兼顾质量和速度):DPM++ 2M Karras (20 -30步) 、UNIPC (15-25步)
- 质量较高:DPM++ SDE Karras
- 稳定复现:不选后缀a / SDE,反之则追求多样性
提示词相关性(CFG Scale)

引导AI按照提示词绘制的程度,推荐7~12,如果过高会出现变形。
种子(Seed)
控制噪声图的产生,以控制画面内容一致性
出图尺寸

即生成图像的分辨率,默认为512×512,对设备(显存)要求较高。由于模型训练数据都比较小,因此将尺寸设置过高会出现多人的情况,最高在1000上下即可。这样生成的图像较为模糊,可以通过高清修复、后期处理、图生图等方式放大图像。
生成批次

AI绘画具有不确定性,可以让AI在一组提示词下一次性生成多张图片。(来一发十连抽)
参考资料