Linux命令执行顺序控制与管道
命令执行顺序的控制
-
通常情况下,使用命令行都是输入完一条指令然后立即执行,然后再输入下一条指令。如果需要一次输入多条指令,再一并执行的话,可以使用
;将多条指令隔开来,在一行里写下,那么在按下Enter的时候,会一次性执行完输入的全部命令。 -
但如果在顺序执行命令时,前面的命令执行不成功,而后面的命令又依赖于上一条命令的结果,那么就可能会造成花了时间,最终却得到一个错误结果的情况,并且有时还不能直观的看出是否正确执行。那么这时就需要有选择性地执行命令,比如上一条命令执行成功后才继续执行下一条,否则应该如何处理。比如使用一个
witch来做判断,如果安装了cowsay命令就执行,否则什么也不做:1
which cowsay>/dev/null && cowsay -f head-in ohch~
其中
&&符号前的内容是执行条件,作为&&后语句是否执行的前提判断,如果cowsay>/dev/null执行成功,那么会返回结果0,&&后的语句就会执行。 -
同样的,shell中也有类似于逻辑或的
||,在此处与&&做出相反的结果,即当||前的语句执行结果≠0时,才执行后方的语句,比如如果未安装cowsay命令,那么显示出未安装提示:1
which cowsay>/dev/null || echo "cowsay has not been install, please run 'sudo apt-get install cowsay' to install"
-
&&和||可以结合起来使用,比如:1
which cowsay>/dev/null && echo "exist" || echo "not exist"

意思为检查是否安装了
cowsay,如果安装了则显示exist,否则显示not exist。上面的语句是先使用&&再使用||,那么如果反过来会出现什么结果呢:1
which cowsay>/dev/null || echo "not exist" && echo "exist"
这一次同时输出了
not exist和exist的结果,因为&&后的语句执行条件是前一句执行成功,而在执行||判断时返回结果≠0,所以执行了||后的语句,从而也执行了&&后的语句。


管道
- 管道是一种通信机制,通常用于进程间的通信(也可通过socket进行网络通信),它表现出来的形式就是将前面每一个进程的输出(stdout)直接作为下一个进程的输入(stdin)。
- 管道又分为匿名管道和具名管道。在使用一些过滤程序时经常会用到的就是匿名管道,在命令行中由
|分隔符表示,|在前面的内容中我们已经多次使用到了。具名管道简单的说就是有名字的管道,通常只会在源程序中用到具名管道。
管道的使用
-
现在尝试查看
/etc下有那些文件和目录:1
ls -al /etc
输出的内容比较多,此时不妨使用管道将
ls输出的结果使用less查看:1
ls -al /etc | less
cut命令
-
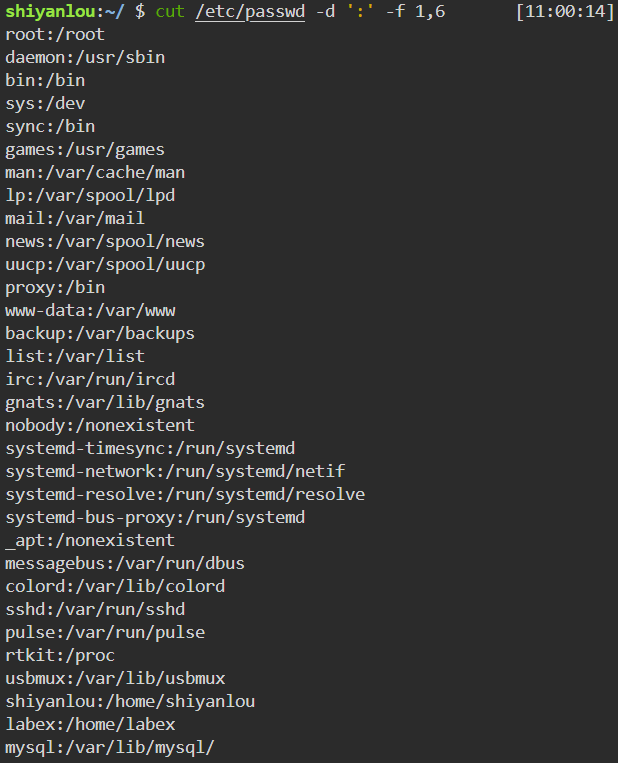
cut命令用于打印每一行的某一字段,比如现在需要打印/etc/passwd文件中以:位分隔符的第一个字段和第六个字段分别作为用户名和其家目录:1
cut /etc/passwd -d ':' -f 1,6
-
打印
/etc/passwd文件中每一行的前N个字符:1
2
3
4
5
6
7
8# 前五个(包含第五个)
cut /etc/passwd -c -5
# 前五个之后的(包含第五个)
cut /etc/passwd -c 5-
# 第五个
cut /etc/passwd -c 5
# 2到5之间的(包含第五个)
cut /etc/passwd -c 2-5
grep命令
-
grep命令用于在文本中或stdin中查找匹配字符串,如果结合正则表达式可以实现复杂切高效的查找和匹配,一般格式为:
1
grep [命令选项]... 用于匹配的表达式 [文件]...
-
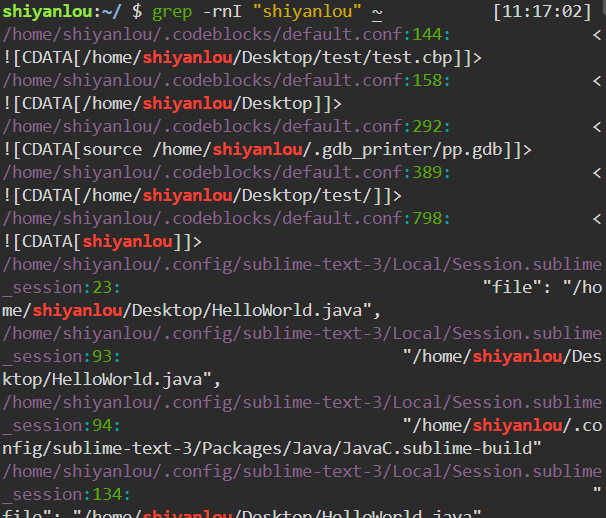
比如,搜索
/home/shiyanlou目录下所有包含shiyanlou的文本文件,并显示出所在文本中的行号,其中-r表示地柜搜索子目录中的文件,-n表示打印匹配项的行号,-I表示忽略二进制文件:1
grep -rnI "shiyanlou" ~
-
同时也可以使用正则表达式,比如查找以
yanlou结尾的字符串:1
export | grep ".*yanlou$"

wc命令
-
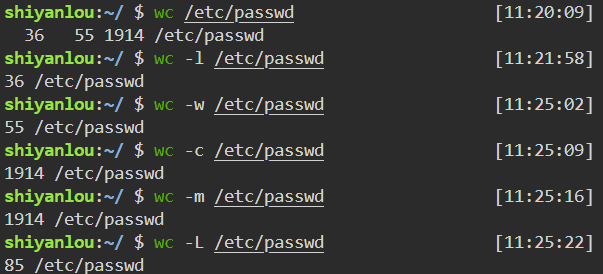
wc命令是简单小巧的计数工具,用于统计并输出一个文件中行、单词和字节的数目,比如输出/etc/passwd文件的统计信息:1
wc /etc/passwd
-
分别只输出行数、单词数、字节数、字符数和输入文本中最长一行的字节数:
1
2
3
4
5
6
7
8
9
10# 行数
wc -l /etc/passwd
# 单词数
wc -w /etc/passwd
# 字节数
wc -c /etc/passwd
# 字符数
wc -m /etc/passwd
# 最长行字节数
wc -L /etc/passwd对于西文字符,一个字符就是一个字节,对于中文字符,一个汉字通常不小于2字节,视编码而定。
-
再结合管道,统计
/etc下所有目录数:1
ls -dl /etc/*/ | wc -l


sort命令
-
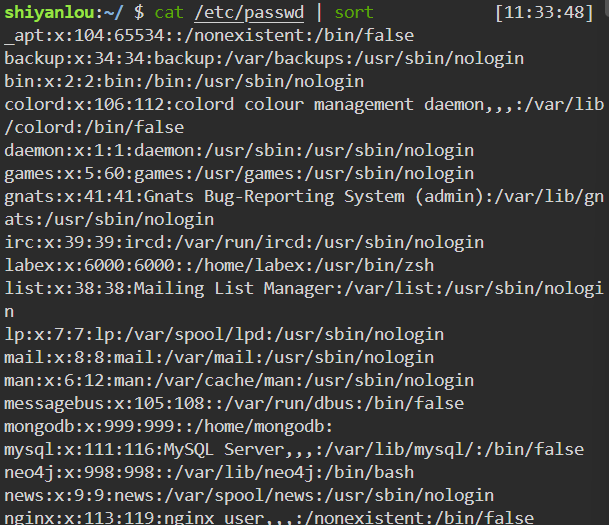
sort命令用于排序,即将输入按照一定方式进行排序,然后再输出,支持的排序方式包括但不限于:字典排序,数字排序,按月份排序,随机排序,反转排序,指定特定字段进行排序…… -
默认为字典排序:
1
cat /etc/passwd | sort
-
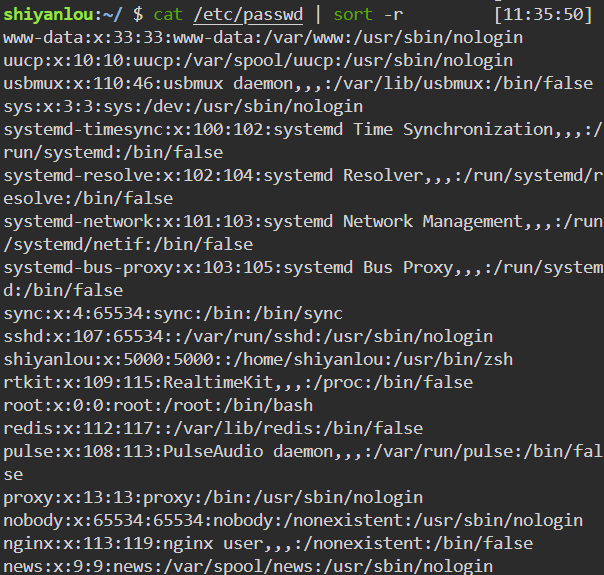
反转排序:
1
cat /etc/passwd | sort -r
-
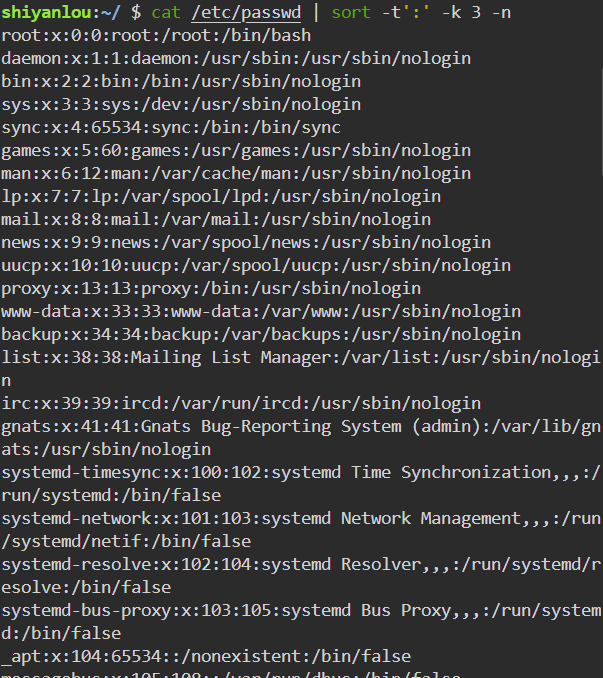
按照特定字段排序:
1
cat /etc/passwd | sort -t':' -k 3
-t参数用于指定字段的分隔符,这里是以":"作为分隔符;-k 字段号用于指定对哪一个字段进行排序。这里/etc/passwd文件的第三个字段为数字,默认情况下是以字典序排序的,如果要按照数字排序就要加上-n参数,此处按照分割后的第三个字段(第二个:后的字段)排序:1
cat /etc/passwd | sort -t':' -k 3 -n
uniq命令
-
uniq命令用于过滤或者输出重复行。比如使用history查看最近执行过的命令,但只想查看使用了哪个命令而不需要知道具体干了什么,那么你可能就会要想去掉命令后面的参数然后去掉重复的命令:1
history | cut -c 8- | cut -d ' ' -f 1 | uniq
虽然
uniq去除了大部分重复行,但可以看出这里仍然存在两条ls的记录,这是因为uniq命令只能去除连续的重复行,而非全文去重,如果需要达到全文去重的效果,那么需要对字段先进行排序操作:1
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq
或者:
1
history | cut -c 8- | cut -d ' ' -f 1 | sort -u
-
如果希望查看重复的行,再分别统计重复次数:
1
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -dc
仅查看重复的行,而不统计重复次数:
1
history | cut -c 8- | cut -d ' ' -f 1 | sort | uniq -D







